DOM = Document Object Model.
It creates a standard from/way that we can access and manipulate documents. DOM is a programming API for both XML and also HTML documents . It provides a definition of the structural logic of the documents ,and a wat that a document id accessed and manipulated
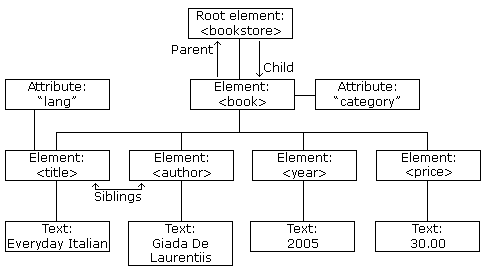
The XML DOM create a tree structure view for the xml document. In here we are able to access all the elements through the tree. Modifying , deleting their content and creating new elements , content(nodes).
: XML DOM Properties :
- x.nodeName – the name of x
- x.nodeValue – the value of x
- x.parentNode – the parent node of x
- x.childNodes – the child nodes of x
- x.attributes – the attributes nodes of x
XML DOM Methods
- x.getElementsByTagName(name) – get all elements with a specified tag name
- x.appendChild(node) – insert a child node to x
- x.removeChild(node) – remove a child node from x
The XML Document Object Model (DOM) class is an in-memory representation of an XML document. The DOM allows you to programmatically read, manipulate, and modify an XML document. The XmlReader class also reads XML; however, it provides non-cached, forward-only, read-only access. This means that there are no capabilities to edit the values of an attribute or content of an element, or the ability to insert and remove nodes with the XmlReader. Editing is the primary function of the DOM. It is the common and structured way that XML data is represented in memory, although the actual XML data is stored in a linear fashion when in a file or coming in from another object.

Citation : https://www.javatpoint.com/xml-dom , David Gassner , https://www.w3schools.com/XML/dom_intro.asp, https://docs.microsoft.com/en-us/dotnet/standard/data/xml/xml-document-object-model-dom
